venvで構築した仮想環境内にインストールしたパッケージがvscodeで認識されない問題の解決
記事の目的
標題の症状に対する解決策のメモ
症状
標題の通り。venvで仮想環境を構築し、仮想環境内でインストールしたパッケージをvscode内で使用しようとしたがModuleNotFoundErrorが発生してしまった。vscodeのインタープリターは仮想環境にあるPythonを指定している。
結論
vscodeがインストールしたパッケージを探しに行けるように設定する。
参考サイト
Visual Studio Codeでライブラリやモジュールが could not be resolved になる時の対処法 | Start Lab | Python特化の公式認定スクール
状況
- venvで仮想環境を構築
- 仮想環境を有効化し、仮想環境内で必要なパッケージをインストール
- vscodeでインタープリターを選択し、仮想環境のPythonへのパスを指定
- 2.でインストールしたパッケージをインポートするコードを作成したところ、"ModuleNotFoundError"が発生→問題発生
原因と対策
vscodeがインストールしたパッケージへのパスを見つけられていないことが原因。vscodeの設定にパッケージへのパスを追加することで解決する。
以下に手順を示す。
1. Powershell(PS)やコマンドプロント(CMD)でパッケージのパスを確認する。
PS、CMDでパスを確認し、ルートから「site-packages」までのパスをコピーしておく。

「ファイル」→「ユーザー設定」→「設定」から設定画面を開く。

設定画面の「設定の検索」欄に「extra path」と入力する。

「Extra Paths」の「項目の追加」に先ほどコピーしたパスを貼り付け、「OK」を押す。

以上でパッケージへのパスがvscodeに認識されるようになる。
Jupyter Notebookで"500 : Internal Server Error"が生じる
問題
Jupter Notebookをupgradeしたところ、以前は開くことのできていたPythonファイルを開こうとすると"500 : Internal Server Error"エラーが生じてしまうようになった。
解決策
以下2つのコマンドを実行したところ、解決した。
$ pip install --upgrade jupyterhub $ pip install --upgrade --user nbconvert
参考にしたサイト
https://stackoverflow.com/questions/36851746/jupyter-notebook-500-internal-server-error
Visual studio codeでmarkdown+TeXで書いた数式を含む文書をPDFに変換する方法
概要
Visual Studio Code(以下vscode)でTeXで書いた数式を含む文書を作成し、それをPDFに変換しようとすると数式がTeXにより変換されず、コードのまま出力されてしまう。そこで正しく数式が表示されるような方法を調査した。
前提条件
vscodeで数式を表示させるために、以下の拡張機能はインストールされているものとする。
Markdown Preview Enhanced - Visual Studio Marketplace
vscodeのプレビューで数式を表示できるようにする拡張機能である。
Markdown PDF - Visual Studio Marketplace
結論
方法は3つある。最終的に以下に示した3.を採用することにした。
- 一度HTMLに変換し、それをブラウザで開いてブラウザの印刷機能でPDFに変換する。
- vscodeの拡張機能であるMarkdown PDFのテンプレートファイルを書き換えてTeXを有効にする。
- vscodの拡張機能であるMarkdown Preview Enhancedの機能を用いて、Chromeを用いてPDFに変換する。
1.の方法が一番分かりやすい。具体的な方法は以下の記事が詳しい。
https://blog.takunology.jp/entry/2020/06/26/112933
但しHTMLに変換→ブラウザで開く→ブラウザでPDFに変換(印刷)というステップを踏む必要があり、少々面倒である。 2.の方法は、はじめ採用しようと思っていたが正しく設定しないとPDFのページが2倍に増えてしまうという症状が生じるという記載があったため避けることにした。なお、以下の参考ページの通りに行えばそのような問題は生じないようである。
VScodeでMarkdownからPDF出力で数式を綺麗に表示する方法 | アホなりに考えてみる
上記のような理由から、結局3.の方法を採用することにした。3.の方法は1.の作業を自動で行ってくれるようなものであり、拡張機能がhtml生成→PDF変換を行ってくれているようである。1クリックで完了するため現時点ではこの方法が最良ではないかと考えている。
症状
解決策を説明する前に画像を交えて症状を説明しておく。
まずvscodeのプレビュー画面では正常にTeXが認識され、数式が表示されていることが分かる。ここでvscodeのコード画面で右クリックしコンテキストメニューを表示させ、そこから"Markdown PDF: Export(pdf)"をクリックしてPDFを生成してみる。
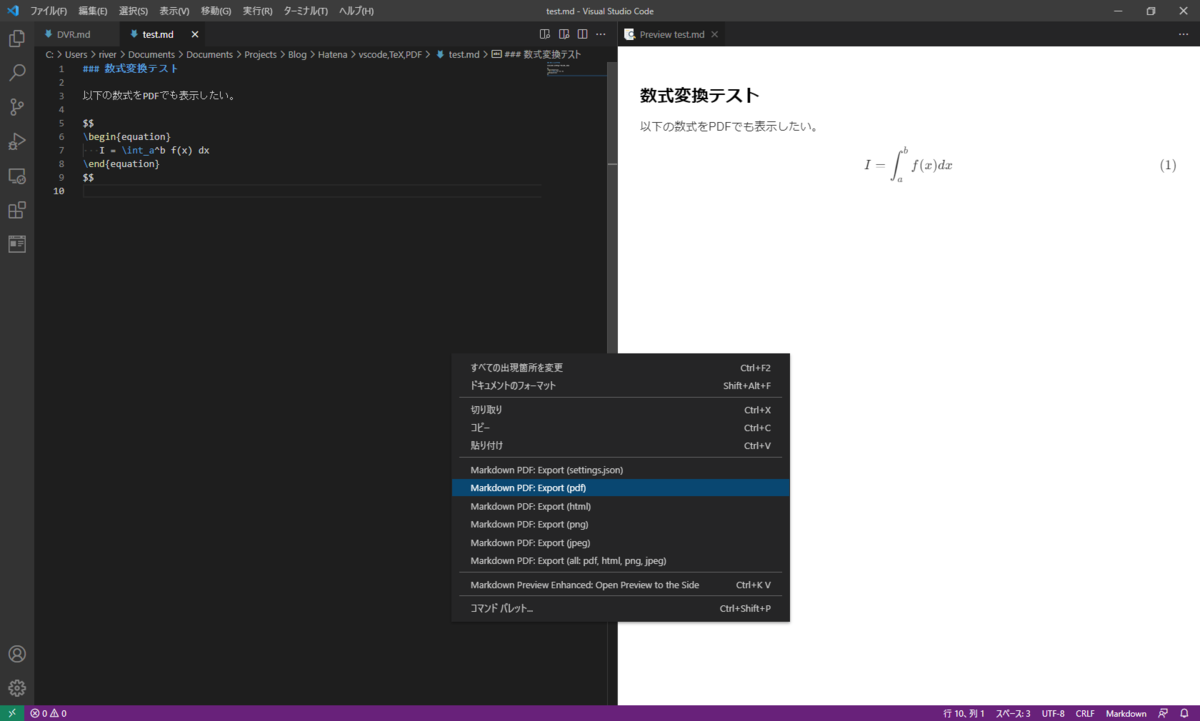
生成されたPDFを開いたものが以下である。数式が変換されず、生のコードが表示されてしまっていることが分かる。

解決策
方法はいたって簡単で、プレビュー画面で右クリックし、コンテキストメニューの中にある"Chrome(Puppeteer)"→"PDF"の順に選んでクリックするだけである。
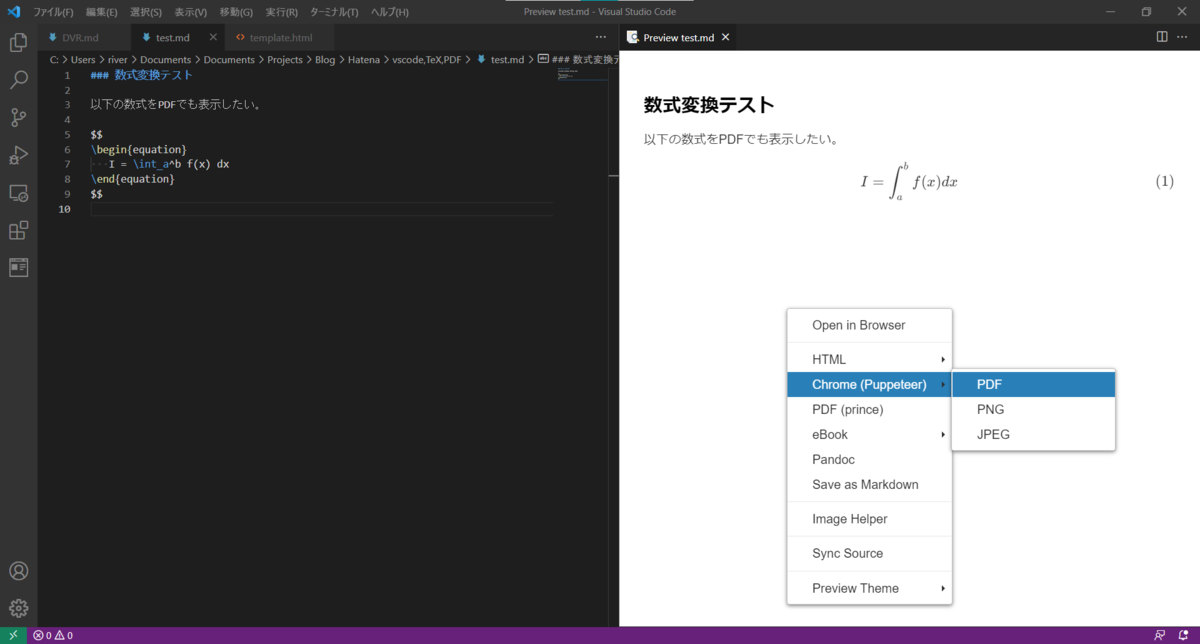
PDFはmarkdownファイルと同じフォルダに生成されるので、それを開くと以下のように正しく数式が表示されていた。

Markdown PDFの機能と若干異なるのは、この方法で生成されたPDFファイルにはファイル名や日付といった情報が表示されない点である。あくまでvscodeのプレビューで表示されたままをPDF変換してくれるようである。
以上
Pandasのilocに配列を与えて特定の要素を取得する方法について
ilocとは
Pandasのilocは絶対値座標で要素を取得することのできる属性である。
pandasで任意の位置の値を取得・変更するat, iat, loc, iloc | note.nkmk.me
本記事で言いたいこと
取得する要素の指定は整数の配列で行うこともできるが、この時の配列は昇順・降順になっている必要はなく、配列内で指定した数列の順序に従い取得される。
例
適当なDataFrameオブジェクトを作り確かめる。
import pandas as pd df = pd.DataFrame(np.arange(12).reshape(4,3), columns=["A","B","C"]) df
【出力】

整数型の配列を作り特定の行を抽出してみる。 この時、あえて行の順番を昇順・降順のどちらでもないようにしてみる。
list1 = [2,3,0] df.iloc[list1]
【出力】

列の取得も同様に行うことができる。
list2 = [2,0] df.iloc[list1, list2]
【出力】

Kerasによるお試しMNIST手書き文字認識
目的
Deep Learningの初歩であるMNISTの手書き文字認識を通して機械学習フレームワークの使い方を学んだので記録する。
参考
本記事は以下のページを参考にしている。そのため記述やコメントについてはほとんど重複している。 TensorFlow(TF)のバージョン違いにより修正した箇所や少し詳しい説明が欲しいと思ったところには独自に追記しているので、その箇所は参考になるかもしれない。
環境
以下のコードは全てGoogle Colaboratory上で動かしている。無償枠を利用しており、Colab Proは利用していない。
概要
大まかには下図のような流れで進める。

実装
1. ライブラリのインポート
まずは必要なライブラリをインポートする。
import os import pathlib import numpy as np import pandas as pd import tensorflow as tf from PIL import Image import matplotlib import matplotlib.pyplot as plt %matplotlib inline
2. 学習データの準備
CSVファイルを作成し、学習の過程を記録する。
# モデルの学習曲線を描画できるようにCSVファイルを作成する。 CSV_FILE_PATH = "trainlog.csv" if not os.path.exists(CSV_FILE_PATH): pathlib.Path(CSV_FILE_PATH).touch()
KerasのデータセットからMNISTのデータを取り込む。
データセットは2つのタプルからなる。 データセット - Keras Documentation
x_train, x_test:shape (サンプル数, 28, 28)の白黒画像データ。uint8型の配列。
y_train_y_test:shape(サンプル数,)のカテゴリラベル(0-9の整数)のuint8型の配列
# MNISTデータをダウンロードして読み込む
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
学習のために入力形式を整え、正規化も行う。
入力形式はKerasの仕様より(ミニバッチサイズ, 横幅, 縦幅, チャネル数(白黒:1, RGB:3)とする必要がある。
# 入力形式を( ミニバッチサイズ, 横幅, 縦幅, チャネル数(白黒:1, RGB:3) )とする。 X_train = X_train.reshape(X_train.shape[0], 28, 28, 1) X_test = X_test.reshape(X_test.shape[0], 28, 28, 1) # グレースケールは0-255で表現されているので、255で割って0.0-1.0に規格化する。 X_train, X_test = X_train / 255.0, X_test / 255.0
3. モデルの作成
ここでいうモデルとは入力・出力の数や中間層の数、活性化関数などの処理の方法を記述したものである。KerasのモデルにはSequentialモデルとFunctional APIとともに用いるモデルクラスの2種類がある。
Sequentialモデルは構造が単純で構築しやすいが簡単なモデルしか表現できず、一方Functional APIを用いるモデルは拡張性が高いが構造が複雑で構築が難しいという印象であったので、まずはSequentialモデルを試すことにした。
Sequentialモデルはニューロンを集めた層(Layer)があり、それらを名前の通り順番(Sequential)につないだ構造をとっていることが特徴である。実際の神経の構造はもっと複雑で層構造にはなっておらず、複雑な接続関係にあるところをこのように単純化し、計算しやすくしたたところがSequentialモデルの良い点ではないかと思われる。 直感的な説明は以下のページが詳しい。
Sequentialモデルの層の中の構造についてもいくつか選択肢がある。今回はこのうち最もよく使われるDenseというタイプの層を用いる。これは層内にある各ニューロンが前の層にある全てのニューロンの出力を受け取り、自分自身も次の層にある全てのニューロンに出力するという性質を持つ。図にすると下のようになる。

1つのニューロンには1つの活性化関数がセットになっており、前層のニューロンからの入力の和にバイアスを加えたものに対して非線形な変換を行い出力を決める。

活性化関数にもいくつか選択肢がある。今回は中間層の活性化関数としてReLuを、出力層の活性化関数としてSoftmaxを用いた。 各種活性化関数の説明については以下の記事が詳しい。なぜ非線形である必要があるかについて明確に述べられていてよかった。
活性化関数のまとめ(ステップ、シグモイド、ReLU、ソフトマックス、恒等関数) - Qiita
# モデルの作成 model = tf.keras.models.Sequential([ # (None, 28, 28) -> (None, 784); 28x28の2次元データを1次元にする。 tf.keras.layers.Flatten(input_shape=(28, 28), name='input'), # Layer1: Linear mapping: (None, 784) -> (None, 512); ここで"None"は任意の正の整数を受けることを意味する。バッチサイズが入る。 # Denseは全ユニットを結合する層であることを表す。nameで層の名称を付けることができる。 tf.keras.layers.Dense(512, name='fc_1'), # Activation function: ReLU; 第1層の活性化関数にReLUを指定する。 tf.keras.layers.Activation(tf.nn.relu, name='relu_1'), # Layer2: Linear mapping: (None, 512) -> (None, 256) tf.keras.layers.Dense(256, name='fc_2'), # Activation function: ReLU tf.keras.layers.Activation(tf.nn.relu, name='relu_2'), # Layer3: Linear mapping: (None, 256) -> (None, 256) tf.keras.layers.Dense(256, name='fc_3'), # Activation function: ReLU tf.keras.layers.Activation(tf.nn.relu, name='relu_3'), # Layer4: Linear mapping: (None, 256) -> (None, 10) tf.keras.layers.Dense(10, name='dense_3'), # Activation function: Softmax tf.keras.layers.Activation(tf.nn.softmax, name='softmax') ]) # View model architecture model.summary()
今回構成したのは中間層が3層、入力層のニューロン数が28×28=784個、中間層のニューロン数が前から順に512、256、256、出力数が0~9の10個、中間層の活性化関数がReLu、出力層の活性化関数がSoftmaxであるようなモデルである。
構成したモデルは<モデルのインスタンス名>.summary()で確認することができる。
4. コンパイル
コンパイルとは構築したモデルに教師データを与えた時にどのように学習するかを指定する作業である。この時点ではまだデータを与えて学習はさせないので処理に時間はかからない。
コンパイルは3つの引数をとる。
- 最適化アルゴリズム(optimizer)
計算結果と教師データの比較からどのように学習するかを指定する。 - 損失関数(loss)
最適化する際に用いる関数を指定する。損失関数の値が小さくなるように最適化が進む。 - 評価関数(metrics)
学習とは無関係にモデルの性能評価のために用意する関数である。
最小二乗法の手順でいうと損失関数は変数と目標の差分の2乗和をとることに、最適化アルゴリズムは損失関数の偏微分を0とした連立方程式を解くことに相当する理解した。 では評価関数とは何か?公式文書には
モデルの性能を測るために使われます.
とあるがそれだけでは要領を得ない。個人的には以下の記事の「学習を評価する指標」の説明が分かりやすかった。
入門 Keras (6) 学習過程の可視化とパラメーターチューニング – MNIST データ | 株式会社インフィニットループ技術ブログ
記事の説明は正解・不正解の2通りの場合を例にとっているため厳密には今回と同じではないが、正答率にも定義がいくつかあり、そのどれを重視するかという観点で評価関数の種類を選ぶ必要があるということを理解した。
今回は最適化アルゴリズムにAdam、損失関数にsparse_categorical_crossentropyを、そして評価関数にaccuracyを用いた。
# Compiling # コンパイルは3つの引数をとる。「最適化アルゴリズム」, 「損失関数」, 「評価関数」 # 最適化アルゴリズム(optimizer):計算結果と教師データの比較から、どのように学習するかを指定する。 # 損失関数(loss):最適化する際に用いる関数。損失関数の値が小さくなるように最適化が進む。 # 評価関数(metrics):学習とは無関係にモデルの性能評価のために用意する関数 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
5.コールバック
学習の過程を可視化するためにコールバック関数を用いて基礎統計量を出力させる。 今回はCSVLoggerを用いた。
keras.ioコールバック - Keras Documentation
# モデルの学習時に呼ばれるコールバック関数を指定
callbacks = []
callbacks.append(tf.keras.callbacks.CSVLogger(CSV_FILE_PATH))
6. 学習
学習データと教師データを用いてモデルを学習させる。fitメソッドを用いて学習を行う。指定するパラメータとその意味は以下の通り。
batch_size
学習データからこの値で指定した数だけランダムにデータを抜き出してモデルを学習させる。
CNNでは複数回学習を繰り返して最適化していく必要があるが、一度に全てのデータを用いてしまうと1回しか学習できない。そこで学習データの全体から一部を抽出して何度も学習させる。さらにその抽出をランダムにすることで特定のデータにのみ最適化されない汎用的なモデルを作ることができる。epochs
上述の学習データの全体から一部を抽出して学習を繰り返す回数を指定する。verbose 進行状況の表示方法を指定する。
validation_data
検証に用いられるデータを指定する。callbacks
学習時に呼ばれるコールバックのリストを代入する。前節でリスト形式でコールバックを指定していたのはこの入力仕様に合わせるためであった。
# Train model # batch_size: 勾配更新毎のサンプル数を示す整数 # epochs: 学習を繰り返す回数。学習データからbatch_size分だけランダムに抽出し、学習を繰り返す。 # verbose: 整数.0,1,2のいずれか.進行状況の表示モード.0 = 表示なし,1 = プログレスバー,2 = 各試行毎に一行の出力. # validation_data: 検証に用いられるデータ。 # callbacks: 訓練時に呼ばれるコールバックのリスト history = model.fit(X_train, y_train, batch_size=100, epochs=30, verbose=1, validation_data=(X_test, y_test), callbacks=callbacks)
7. 評価
学習済みモデルの評価を行うために、訓練データに対する正答率と検証データに対する正答率を出力してみる。
# 学習済みモデルの評価 # 訓練データに対する正答率 train_loss, train_acc = model.evaluate(X_train, y_train, verbose=1) print("loss(train): {:.4}".format(train_loss)) print("accuracy(train):{:.4}".format(train_acc)) print() # 検証データに対する正答率 test_loss, test_acc = model.evaluate(X_test, y_test, verbose=1) print("loss(test): {:.4}".format(test_loss)) print("accuracy(test): {:.4}".format(test_acc))
学習データに対しては損失関数は0.00264、正答率は0.999程度とよく学習できているように見える。一方検証データに対しては損失関数が0.101、正答率が0.984であり、損失関数は40倍大きく、正答率は1%ほど下がっていることが見て取れる。

学習が正しくできているかを視覚的に確認するため、コールバックで記録していた学習記録を呼び出してグラフに表示する。
# 出力していたCSVファイルを読み込み、学習曲線を描画する。
df = pd.read_csv(CSV_FILE_PATH)
df.head()
headメソッドでデータフレームの構造を確認している。

matplotlibで結果を描画した。epoch数(学習またはテストデータから一部を取り出して学習または検証する回数)が増えるごとにtrain dataはlossが減ってaccuracyが上がっていることが分かる。検証データに対してはlossが0.1近辺を、accuracyは0.98近辺をうろついていることが見てとれる。検証データに対してはlossが一度下落した後に徐々に増加している傾向があり、accuracyは低いところからスタートして徐々に増加している傾向があるように見えるのだが、これはepoch数が少ないためであろうか。
epochs = df["epoch"].values train_acc = df["accuracy"].values train_loss = df["loss"].values test_acc = df["val_accuracy"].values test_loss = df["val_loss"].values plt.plot(epochs, train_loss, label="train data") plt.plot(epochs, test_loss, label="test data") plt.xlabel("epochs") plt.ylabel("loss\n(categorical crossentropy)") plt.legend(loc="upper right") plt.show() plt.plot(epochs, train_acc, label="train data") plt.plot(epochs, test_acc, label="test data") plt.xlabel("epochs") plt.ylabel("accuracy") plt.legend(loc="lower right") plt.show()

8. 検証
最後に学習済みモデルを用いて実際に推論を行い、与えた手書き画像に対して正しく推論ができているかを確かめる。推論は<モデルのインスタンス名>.predictで行う。なお、predict_classesというメソッドはTensorFlowのVer2以降では無くなっており、Ver2ではpredictメソッドが実装されているとのことであった。predictメソッドでは出力の確信度(入力に対して出力のどれが最も正しそうか)を配列で返す仕様になっているため、確信度の最も高い要素番号を出力している。
とりあえず3つほど表示すると以下の通り。
for i in [0,1,2]: y_true = y_test[i] # predict_classesはTensorFlowのVer1系には存在するが、Ver2以降では無くなっている。(参考: https://teratail.com/questions/358850 ) # y_pred = model.predict_classes(X_test[i].reshape(1,28,28))[0] # predictメソッドは使えるのでそれを用いる。predictメソッドはそれぞれの出力(今回は0~9の数字)の「確信度」を配列で返すので # 一番大きな値を抽出する。(参考: https://www.tensorflow.org/tutorials/keras/classification?hl=ja ) y_pred = np.argmax( model.predict( X_test[i].reshape(1,28,28) )[0] ) print("y_test_pred", "(i="+str(i)+"): ", y_pred) print("y_test_true", "(i="+str(i)+"): ", y_true) print("X_test", "(i="+str(i)+"): ") plt.imshow(X_test[i].reshape(28,28), cmap='gray') plt.show()

matplotlibのsubplotを用いて4行5列のパネル状に表示すると以下の通り。正しく推論できているかを"True"、"False"で表示した。
fig = plt.figure(figsize=(12, 8)) ROW = 4 COLUMN = 5 for i in range(ROW * COLUMN): y_true = y_test[i] # predict_classesはTensorFlowのVer1系には存在するが、Ver2以降では無くなっている。(参考: https://teratail.com/questions/358850 ) # y_pred = model.predict_classes(X_test[i].reshape(1,28,28))[0] # predictメソッドは使えるのでそれを用いる。predictメソッドはそれぞれの出力(今回は0~9の数字)の「確信度」を配列で返すので # 一番大きな値を抽出する。(参考: https://www.tensorflow.org/tutorials/keras/classification?hl=ja ) y_pred = np.argmax( model.predict(X_test[i].reshape(1,28,28) ) ) if y_true == y_pred: result = "True" # Correct answer from the model else: result = "False" # Incorrect answer from the model plt.subplot(ROW, COLUMN, i+1) plt.imshow(X_test[i].reshape(28,28), cmap='gray') plt.title("No.{} - {}\ny_true:{}, y_pred:{}".format(i, result, y_true, y_pred)) plt.axis("off") fig.tight_layout() fig.show()

まとめ
MNISTの手書き文字認識を試し、実際に手書き文字が正しく認識できていることが確認できた。本来は自分で書いた手書き文字を認識させて正しく数字を認識できているか確認したいところではあるが、Google Colab上にローカルのデータをアップロードする方法について調べる必要があるため今回は省いた。 TensorFlowというだけあってちゃんとデータやメソッドの引数で与える配列のshapeを意識して実装しないとエラーが出てしまい、悩むこともあった。とはいえ全体としてkerasは手軽にCNNを実装でき、方法も明確であってとても良いと感じた。さらに自前で高性能なGPUが無くとも無料でこういった計算ができてしまうGoogle Colabは素晴らしいと思う。
Windowsのキーボードトラブル
症状
以前から頻発していたキーボードのトラブルが再発した。 ノートPCを使用している。 アルファベット、数字と記号のキーが反応しなくなった。記号のキーで唯一「\」のみが反応した。 外付けのキーボードを挿しても同じ状況であることから、キーボードのハードウェアの問題ではなさそう。
以前はWindowsアップデートで改善した。根本的な問題解決かと思ったが、再発したため主原因ではなかった模様。
今回も再度Windowsアップデートを実行した。また、DELLのファームウェアアップデートも行った。 しかし症状は改善しなかった。
キーボードのドライバを再インストールと改善するという情報があったため試した。
デバイスマネージャで標準PS/2キーボードのドライバアンインストールし、PCを再起動した。 (アンインストールすると再起動を促される) 再起動するとPS/2キーボードのドライバは再度インストールされており、キーボードも正常に動作するようになった。
TeXで複数行にわたる括弧を書く方法
1. \left, \right の中にalignを入れる
\begin{equation*} \left\{ \begin{align*} x = a + b \\ y = c + d \end{align*} \right. \end{equation*}

2. \begin{cases} … \end{cases}を用いる
\begin{equation*} \begin{cases} x = a + b \\ y = c + d \end{cases} \end{equation*}

見た目の違いとしては"cases"を用いる方が左括弧のサイズが少し大きいことぐらい。align環境の使える1.の方法が良い気がしている。